Ahoj, par postrehu z dnesni zkousky.
Priklady v testiku mely tak 90% coverage na foru

Z novinek si pamatuju treba:
Bud L libovolny jazyk, potom jazyk
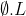
:
a) je podmnozinou L
b) je regularni
c) je nadmnozinou L
d) rovna se L
(spravne samozrejme a,b - prazdny jazyk neprijima zadne slovo (pozor - ani
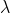
), takze zretezeni se nema ceho chytit a vysledkem je opet prazdny jazyk).
Pak tam bylo regularni pumping lemma, kde ale ve zneni "zapomnel" |v| > 0. Odpoved, ze plati pouze pro regularni jazyky, spravna nebyla (myslim, ze na vyber byla cela Ch. hierarchie)
Umrtnost na testu nebyla moc velka (rekl bych pod tretinu).
Z velkych prikladu jsem zaslechl napr.:
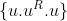
,
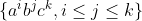
,
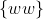
,
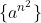
, nekdo sestrojoval TS. Pro tyto jazyky byly rozlicne ukoly - zaradit (bez hintu, kam patri); dokazat, ze patri prave do dane tridy; sestrojit gramatiku/automat pro dany jazyk; prevest automat<->gramatiku. Plus samozrejme dokazat pouzite vety (coz ale neznamena, ze musite rekurzivne dokazat vsechna tvrzeni potrebna pro dukaz jine vety... staci se o nich treba jen zminit, napsat zneni, nebo tak).
Co se rozhodne naucte (a hlavne pochopte!) jsou dukazy pumping lemmat a Nerodovky... Na tom to stoji i pada.
Nevim, jestli to byla zvlastnost dnesni zkousky, nebo je to beznejsi jev, ale po pisemne casti nas doc. pustil pryc a sel obhajovat diplomky a obedvat... Takze jsme si mohli pred ustni casti v klidu vsechno najit
Mym ukolem bylo zaradit jazyk
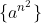
. Dukaz, ze neni bezkontextovy, najdete ve sbirce resenych prikladu na Studnici. Psal jsem tedy kontextovou gramtiku. Idea gramatiky by byla hned, ale pak jsem se hodinu paral s tim, abych opravdu mel vsechna pravidla nezkracujici a zbavil se prepisovani na lambdu.
Gramatika fungovala asi nasledovne. Kdyz si rozepisete prvnich par clenu posloupnosti
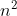
, je to 1, 4, 9, 16, 25... Rozdil mezi sousednimi cleny se vzdy zvysuje o dva, coz je dusledek nasledujiciho vztahu:
^2-n^2 = n^2 + 2n + 1 - n^2 = 2n + 1)
. Takze gramatika si drzi vlevo v "citaci" 2n+1 znaku a vzdy se rozhodne, ze je bud vsechny prepise na
a, nebo vytvori 2n+1 novych
acek a zvetsi
n o jednicku. Tot cela myslenka.
S - pocatecni symbol, L - leva zarazka (soucast citace), C - soucast citace, D - signal, ze chci pridavat
acka, E - slouzi pro presun
acek vpravo a pak signalizuje, ze vsechna pozadovana
acka byla vytvorena a zarazena, F - rozhodli jsme se skoncit, A - prepise se ve vhodnou chvili na
a
Kód: Vybrat vše
S -> lambda | a | LCCa
LC -> LAEED //zvetsujeme n o jednicku (pridame dva znaky) + posleme vpravo signal, ze chceme pridavat
DC -> DD //posilame vpravo signal, ze chceme pridavat acka
D -> EA //vykoname prikaz pro pridani acka
AE -> EA //neni kontextove, prepiseme pomoci 4 pravidel pomoci algoritmu ze slidu; vsechna A putuji vpravo
A -> a
Ea -> Ca //vracime se do puvodniho stavu
EC -> CC
LC -> FC //rozhodneme se skoncit
FC -> FF //posilame signal o konci dale
Fa -> aa //signal o konci dorazil na konec citace, takze uz jen citac prepisu na acka
Pro nazornost derivace:
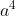
:
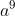
:
Kód: Vybrat vše
S=>LCCa=>*LAEEDDa=>*LAEEEAEAa=>*LEEEEAAAa=>*LCCCCaaaa=>FCCCCaaaa=>*FFFFFaaaa=>*aaaaaaaaa
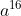
:
Kód: Vybrat vše
S=>LCCa=>*LAEEDDa=>*LAEEEAEAa=>*LEEEEAAAa=>*LEEEEaaaa=>*LCCCCaaaa=>*LAEEDDDDaaaa=>*LAEEEAEAEAEAaaaa=>*LEEEEEEAAAAAaaaa=>*
LCCCCCCaaaaaaaaa=>*FCCCCCCaaaaaaaaa=>*FFFFFFFa^9=>*a^7a^9 = a^16
Pak chtel jeste prevod na automat, tedy na LOA. Stacila napsat idea prevodu tak, jak je na slidech.
Rozdaval jednicky, dvojky i trojky (jestli nekoho od ustni vyhodil, nevim, ale spis myslim, ze ne). Vzdycky se ale ptal, co clovek chce, a kdyz chtel lepsi znamku, nez na jakou to vypadalo, tak mu dal dokazat jeste nejakou vetu nebo tvrzeni, popr. dodelat poradne/opravit dukazy z pisemne casti.
Ahoj, par postrehu z dnesni zkousky.
Priklady v testiku mely tak 90% coverage na foru :)
Z novinek si pamatuju treba:
Bud L libovolny jazyk, potom jazyk [latex]\emptyset .L[/latex]:
a) je podmnozinou L
b) je regularni
c) je nadmnozinou L
d) rovna se L
(spravne samozrejme a,b - prazdny jazyk neprijima zadne slovo (pozor - ani [latex]\lambda[/latex]), takze zretezeni se nema ceho chytit a vysledkem je opet prazdny jazyk).
Pak tam bylo regularni pumping lemma, kde ale ve zneni "zapomnel" |v| > 0. Odpoved, ze plati pouze pro regularni jazyky, spravna nebyla (myslim, ze na vyber byla cela Ch. hierarchie)
Umrtnost na testu nebyla moc velka (rekl bych pod tretinu).
Z velkych prikladu jsem zaslechl napr.: [latex]\{u.u^R.u\}[/latex], [latex]\{a^ib^jc^k, i \leq j \leq k \}[/latex], [latex]\{ww\}[/latex], [latex]\{a^{n^2}\}[/latex], nekdo sestrojoval TS. Pro tyto jazyky byly rozlicne ukoly - zaradit (bez hintu, kam patri); dokazat, ze patri prave do dane tridy; sestrojit gramatiku/automat pro dany jazyk; prevest automat<->gramatiku. Plus samozrejme dokazat pouzite vety (coz ale neznamena, ze musite rekurzivne dokazat vsechna tvrzeni potrebna pro dukaz jine vety... staci se o nich treba jen zminit, napsat zneni, nebo tak).
Co se rozhodne naucte (a hlavne pochopte!) jsou dukazy pumping lemmat a Nerodovky... Na tom to stoji i pada.
Nevim, jestli to byla zvlastnost dnesni zkousky, nebo je to beznejsi jev, ale po pisemne casti nas doc. pustil pryc a sel obhajovat diplomky a obedvat... Takze jsme si mohli pred ustni casti v klidu vsechno najit :)
Mym ukolem bylo zaradit jazyk [latex]\{ a^{n^2} \}[/latex]. Dukaz, ze neni bezkontextovy, najdete ve sbirce resenych prikladu na Studnici. Psal jsem tedy kontextovou gramtiku. Idea gramatiky by byla hned, ale pak jsem se hodinu paral s tim, abych opravdu mel vsechna pravidla nezkracujici a zbavil se prepisovani na lambdu.
Gramatika fungovala asi nasledovne. Kdyz si rozepisete prvnich par clenu posloupnosti [latex]n^2[/latex], je to 1, 4, 9, 16, 25... Rozdil mezi sousednimi cleny se vzdy zvysuje o dva, coz je dusledek nasledujiciho vztahu: [latex](n+1)^2-n^2 = n^2 + 2n + 1 - n^2 = 2n + 1[/latex]. Takze gramatika si drzi vlevo v "citaci" 2n+1 znaku a vzdy se rozhodne, ze je bud vsechny prepise na [i]a[/i], nebo vytvori 2n+1 novych [i]a[/i]cek a zvetsi [i]n[/i] o jednicku. Tot cela myslenka.
S - pocatecni symbol, L - leva zarazka (soucast citace), C - soucast citace, D - signal, ze chci pridavat [i]a[/i]cka, E - slouzi pro presun [i]a[/i]cek vpravo a pak signalizuje, ze vsechna pozadovana [i]a[/i]cka byla vytvorena a zarazena, F - rozhodli jsme se skoncit, A - prepise se ve vhodnou chvili na [i]a[/i]
[code]S -> lambda | a | LCCa
LC -> LAEED //zvetsujeme n o jednicku (pridame dva znaky) + posleme vpravo signal, ze chceme pridavat
DC -> DD //posilame vpravo signal, ze chceme pridavat acka
D -> EA //vykoname prikaz pro pridani acka
AE -> EA //neni kontextove, prepiseme pomoci 4 pravidel pomoci algoritmu ze slidu; vsechna A putuji vpravo
A -> a
Ea -> Ca //vracime se do puvodniho stavu
EC -> CC
LC -> FC //rozhodneme se skoncit
FC -> FF //posilame signal o konci dale
Fa -> aa //signal o konci dorazil na konec citace, takze uz jen citac prepisu na acka[/code]
Pro nazornost derivace:
[latex]a^{4}[/latex]:
[code]S=>LCCa=>FCCa=>*FFFa=>*aaaa[/code]
[latex]a^{9}[/latex]:
[code]S=>LCCa=>*LAEEDDa=>*LAEEEAEAa=>*LEEEEAAAa=>*LCCCCaaaa=>FCCCCaaaa=>*FFFFFaaaa=>*aaaaaaaaa[/code]
[latex]a^{16}[/latex]:
[code]S=>LCCa=>*LAEEDDa=>*LAEEEAEAa=>*LEEEEAAAa=>*LEEEEaaaa=>*LCCCCaaaa=>*LAEEDDDDaaaa=>*LAEEEAEAEAEAaaaa=>*LEEEEEEAAAAAaaaa=>*
LCCCCCCaaaaaaaaa=>*FCCCCCCaaaaaaaaa=>*FFFFFFFa^9=>*a^7a^9 = a^16[/code]
Pak chtel jeste prevod na automat, tedy na LOA. Stacila napsat idea prevodu tak, jak je na slidech.
Rozdaval jednicky, dvojky i trojky (jestli nekoho od ustni vyhodil, nevim, ale spis myslim, ze ne). Vzdycky se ale ptal, co clovek chce, a kdyz chtel lepsi znamku, nez na jakou to vypadalo, tak mu dal dokazat jeste nejakou vetu nebo tvrzeni, popr. dodelat poradne/opravit dukazy z pisemne casti.